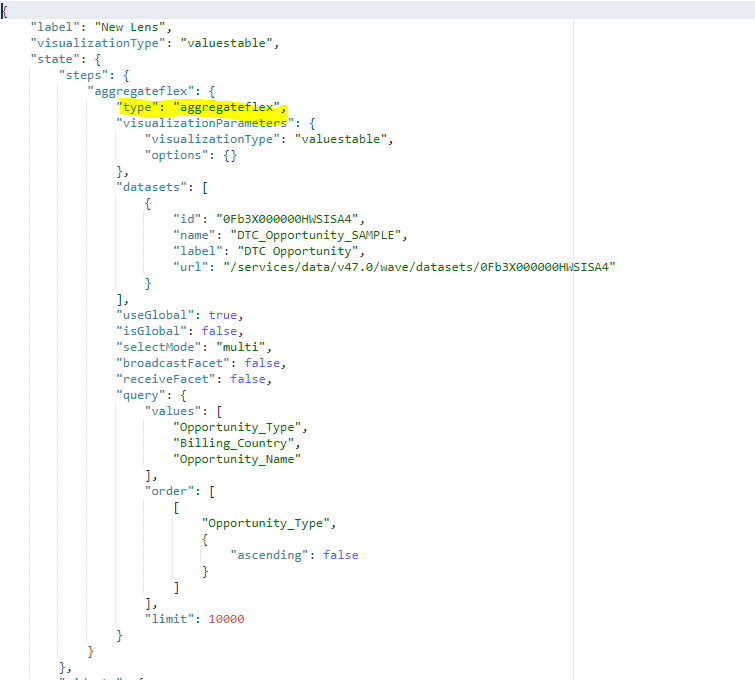
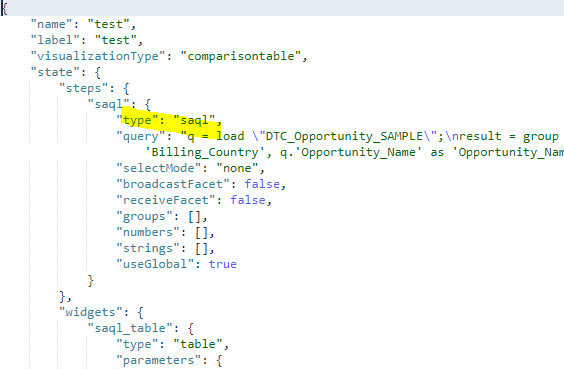
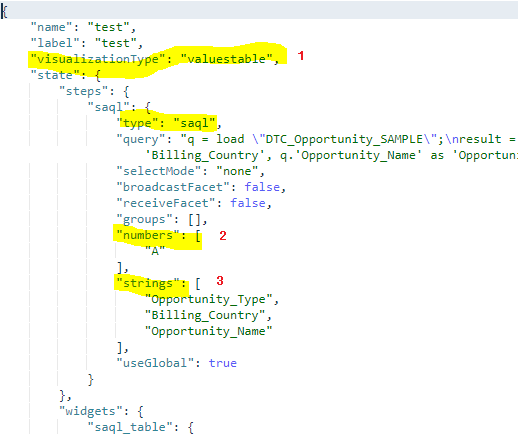
El verano ya está cerca y con él la release Summer ’20 de Salesforce. Ésta, incluye muchas novedades en Einstein Analytics. Tal y como viene siendo habitual, esta nueva versión viene con gran cantidad de nuevas funcionalidades para que no caigamos en el aburrimiento.
Los que estamos desarrollando informes con Einstein Analytics estamos deseando tener en producción
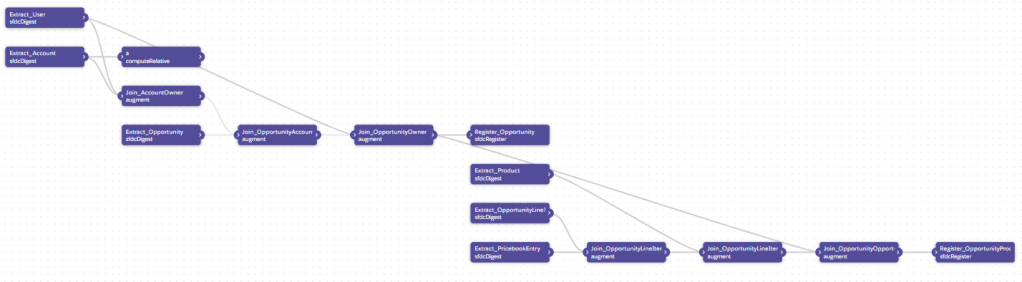
1. Data Prep 3.0 (Beta) 🆒🆒🆒
Esta es la novedad estrella de esta nueva versión (ya lo comentaba en este post).
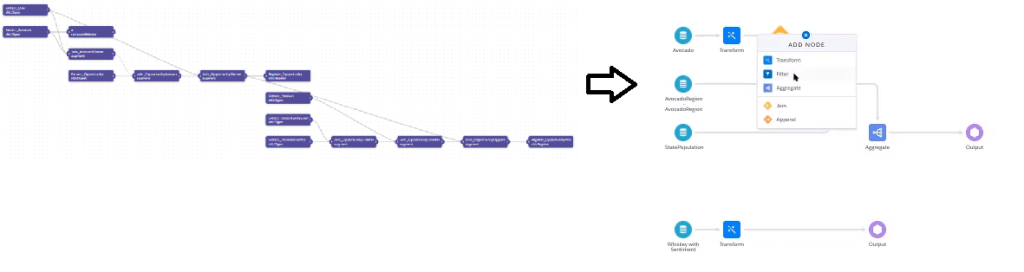
Esta nueva herramienta pretende eliminar la complejidad de los dataflows y recipes actuales a una nueva interfaz en la que se pretende que la mayoría de las acciones sean a través de la interfaz de usuario y menos programáticas. De esta forma la herramienta se hace más user friendly y disminuir el tiempo de aprendizaje.
Link.
2. Detect Sentiment 🙂
Dentro de la nueva herramienta de preparación datos encontramos otra de las novedades: la nueva transformación «Detect Sentiment» (detectar sentimiento).
Esta herramienta permite detectar, dentro de un campo de texto, si en general el texto es: positivo, negativo o neutral. Esto es muy útil si los campos de texto son comentarios de clientes, respuestas de encuentas, etc.
Link.
3. Output connectors ✍️
A partir de esta versión Einstein Analytics será capaz de «escribir» en otros sistemas. Esta funcionalidad también forma parte de la nueva herramienta de preparación de datos. Se presenta como una ampliación de la transformación que registra (guarda) el dataset.
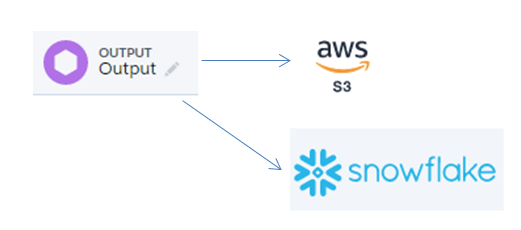
De momento podremos escribir en:
- Amazon S3 (Beta): este conector estará ya disponible en la versión summer ’20 aunque será «beta».
- Snowflake (Pilot): este conector estará disponible solo para los que formen parte del programa piloto.
4. Mejoras en la conexión con Google Cloud👍
Desde hace ya versiones se está apostando mucho por la conexión con Google Cloud. En esta nueva versión de la plataforma este conector viene con mejoras. Se podrán filtrar los datos de los objetos conectados (de Big Query y de Standard SQL) para así no traerlos todos y mejorar la rapidez.
Link.
5. Pivot tables 🆒🆒🆒
Hasta el momento las pivot tables tenían muchas limitaciones. He estado a punto de publicar trucos en SAQL para explicar como añadir múltiples medidas… ¡pero ya no va a hacer falta! A partir de esta nueva versión las pivot tables admiten múltiples medidas.
Además, se podrán formatear mucho más.
Link.
6. Widget de texto ✔️
Después de programar muchos data bindings para añadir texto dinámico: ¡ya se puede hacer con la interfaz de usuario!
Link.
7. Suscripción a una tabla (Beta)
Ahora te puedes suscribir a cualquier widget para que te envíe de forma programada los datos en un fichero de tipo CSV.
Link.
8. Watchlist
Esta funcionalidad aún beta sigue incorporando mejoras:
- Se pueden ver hasta 20 KPIs (indicadores).
- Al seleccionar un KPI se despliega su detalle con la tendencia temporal.
Link.
9. Learning journey👩🎓
Se podrá añadir a los dashboards una guía para que los usuarios aprendan a utilizar el informe.
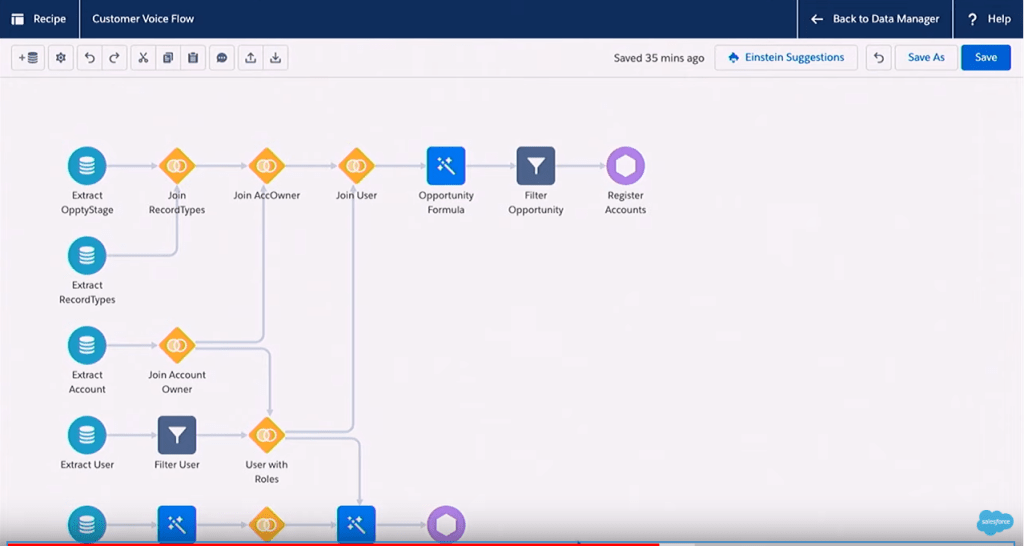
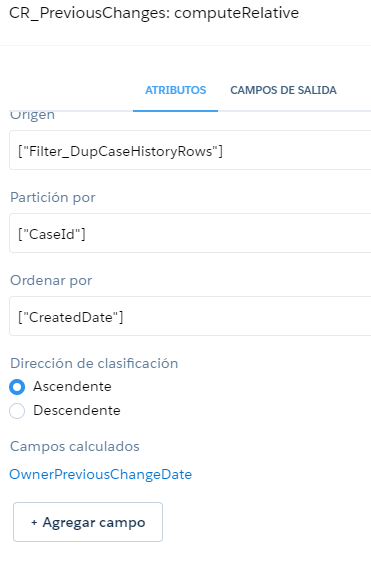
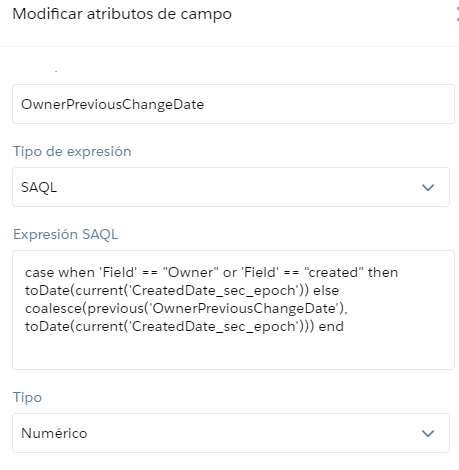
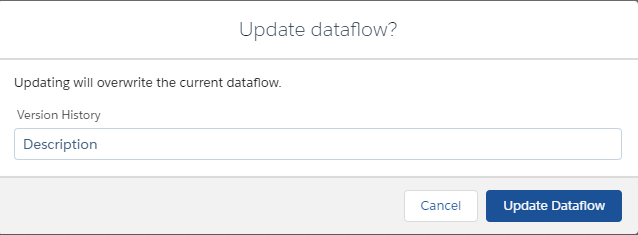
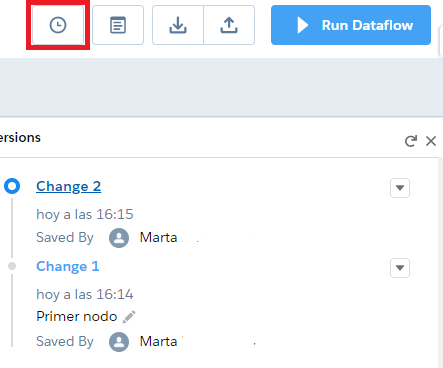
10. Historial en los Dataflows 🆒🆒🆒
Y para acabar otra de las novedades que a mí personalmente me hacen mucha ilusión: ¡que se guarde un historial con las modificaciones en los dataflows!
Hasta el momento la manera más segura de trabajar con los dataflows era guardarse el fichero JSON. Además, si hacías cualquier cambio y querías volver atrás o si cerrabas sin querer, no había forma de recuperar los cambios.
Conclusión
En este post he hecho un resumen de las características que me han parecido más relevantes. Pero hay muchas más, sobre todo respecto la parte de inteligencia artificial (Einstein Discovery).
¡Aquí puedes consultar todas las novedades del verano!